
Finden COVID-19 Nadeln in einem coronavirus Heuhaufen
COVID-19 Forscher auf der ganzen Welt stehen vor einer gewaltigen Aufgabe der Sichtung durch Zehntausende von vorhandenen Corona-Virus-Studien, Suche nach Gemeinsamkeiten oder Daten, die helfen könnten, in Ihrem dringenden biomedizinischen Untersuchungen.
Zur Beschleunigung der Filterung von relevanten Informationen, Sandia National Laboratories hat zusammengebaut eine Kombination von data-mining, machine-learning-algorithmen und Kompression-basierte analytics, bringen die meisten nützliche Daten in den Vordergrund, die auf ein office-Rechner. In seiner anfänglichen Anstrengungen, Ermittler waren nicht in der Lage zu beschneiden 29.000 veröffentlicht coronavirus Studien 87 papers, die von Sprache zu identifizieren und ähnlichkeiten im Charakter, in einer Angelegenheit von 10 Minuten. Das rapid-response-Daten Wissenschaft.
„Medizinische und epidemiologische Experten in der Nähe unmittelbaren Zugang zu den vorhandenen relevanten Forschung, ohne dass die Daten der Wissenschaftler,“ Sandia Informatiker Travis Bauer sagte. „Mit einigen Verfeinerung dieser neue Prozess kann klären Fragen, die unsere Experten für öffentliche Gesundheit müssen beantwortet werden, um fast-track COVID-19 Forschung, insbesondere neue Studien schnell entstehen.“
Die Art der schnellen Reaktion der Wissenschaft ist, um schnell verlässliche Ergebnisse. In einem sieben-Tage-Aufwand, Sandia-Wissenschaftler, konzipiert, konfiguriert, analysiert, getestet und re-analysiert ein experiment helfen, Biosicherheit und öffentliche Gesundheit Experten isolieren Schlüssel coronavirus Dokumente schnell Zugriff auf die wichtigsten Informationen in dem Sieg über die COVID-19-virus.
Bauer und ein team von data scientists, engineers, ein human-factors-Experte und Experten in den Bereichen Virologie, Genetik, public health, biosecurity und biodefense entwickelt und lief zwei verschiedenen such-Studien—eine mit zwei Experten und eine mit drei. Die Experten untersuchten „Stabilität des SARS-CoV-2 in der aerosol-Tröpfchen und anderen matrices,“ gezeichnet von der 18. März US-Department of Homeland Security master-Frage-Liste, soll schnell den aktuellen Stand der verfügbaren Informationen zu staatlichen Entscheidungsträgern und fördern den wissenschaftlichen Diskussionen über die Bundesregierung.
Die Anwendung von algorithmen und Kompression der Daten-Techniken
Daten im Projekt verwendet werden, wurden als Teil der föderalen call-to-action, um die tech-community auf einen „Neuen maschinenlesbaren COVID-19″ – Datensatzes, der zu der Zeit, enthalten 29,315 Forschung Dokumente, die voll von relevanten Themen zum coronavirus. In einem Versuch zu beschleunigen-Experten “ die Fähigkeit zu lernen eine spezifische Frage, Sandia-Forschung—finanziert zunächst durch die Labore Lizenzeinnahmen und dann durch die Sandia Labors ausgerichteten Forschungs-&-Entwicklung Programm—erfolgte in mehreren Etappen.
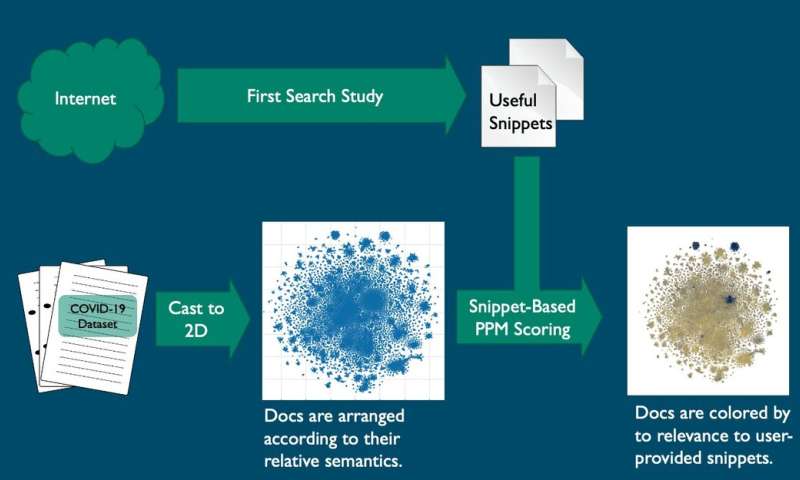
In der Anfangsphase der Studie Virologie, Genetik, public health, biosecurity und biodefense-Experten indiziert die Forschungsarbeiten und geplottet, dass die Informationen in einem zweidimensionalen Diagramm mithilfe von natural language processing-Techniken beruhen auf dem Dokument-Inhalt. Die Dokumente wurden umgewandelt in eine durchsuchbare natürlicher Sprache-matrix und indiziert oder erzielt für die Auffindbarkeit und Relevanz.
Drei weit verbreitete Visualisierungs-algorithmen wurden getestet auf dem 29.000-Dokument festlegen, um zu sehen, welche am besten ordnen Sie die Dokumente in sinnvolle Cluster Bauer sagte.
Auch in der Anfangsphase, die gleichen Experten wurden gebeten, die Suche nach relevanten Artikel zu „Stabilität des SARS-CoV-2 in der aerosol-Tröpfchen und anderen matrices“ mit dem such-system oder engine Ihrer Wahl.
Die Studie Experten festgehalten, was Sie als relevante oder interessante Informationen hilfreich bei der Beantwortung Ihrer COVID-19 Frage und klebte es in ein Microsoft Word-Dokument. Das Dokument mit den Informationen zu den schnipseln, die zu Ihrer Erstellung verwendet wurden erzielt für Artikel basiert auf wie gut Sie beantworteten die Experten Fragen.
Die Schnipsel identifiziert, enthalten COVID-19 und coronavirus Stabilität, Fallstudien, test Matrizen und andere Themen. Die Ergebnisse wurden gezeichnet, als Punkte auf einer zweidimensionalen Diagramms, der angibt, Cluster von relevanten und irrelevanten Beiträgen.
Ein Analyse-Algorithmus in der Prediction by Partial Matching-Daten-Kompression, die dann erzielte alle COVID-19 Dokumente pro snippets. Erzielt wurden verwendet, um die Farbe der Dokumente auf den zwei-dimensionalen Graphen, die Bereitstellung von Clustern von Farbe, zeigen die Experten, wo die relevanten Informationen gefunden werden können. Über 87 gruppierten Dokumente wurden als sehr relevant auf den Graphen; mehr als 23.000 der Dokumente wurden als irrelevant betrachtet.
Experten in der Studie sagen-tools effektiv kategorisiert Ergebnisse haben Potenzial
Nach einem 30-minütigen Sitzung, die Experten wurden gebeten, zu erklären, Ihre Suchbegriffe, wie Sie entschieden haben, welche Artikel zur Ansicht und mit welchen Inhalten Sie waren auf der Suche für jeden Artikel.
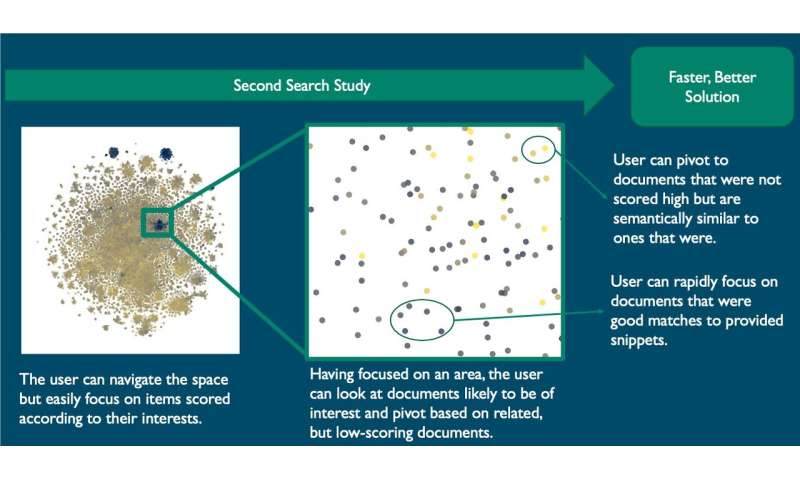
Die Experten interaktiv erkundet die kontrastierenden farbigen Cluster, Stand als Batch COVID-19-zugehörige Dokumente. Sie studieren könnten, irgendwelche Dokumente, um zu bestimmen, ob Sie waren zusammengefasst entsprechend nach Relevanz oder Drehpunkt, um neue snippets.
Die gleichen Experten, die untersucht, die Ergebnisse, sagte, dass die Dokumente wurden genau dosiert nach Relevanz und bot Vorschläge auf die weitere Verfeinerung der Benutzeroberfläche durch die Anzeige von Informationen über Titel, Autoren, Jahr, Zeitschrift und Abstrakt. Die Experten sagten, Sie sahen eine Menge Potenzial mit diesem tool.
„Sogar auf meinem office laptop-computer Sortieren wir Millionen von Dokumenten und stellen diese dem Benutzer zur Verfügung“, betonte Bauer. Er bestätigte, dass einige algorithmen verwendet, um mehr Differenzierung und visual clustering, aber das tuning der algorithmen wird die Leistung verbessert.